Background
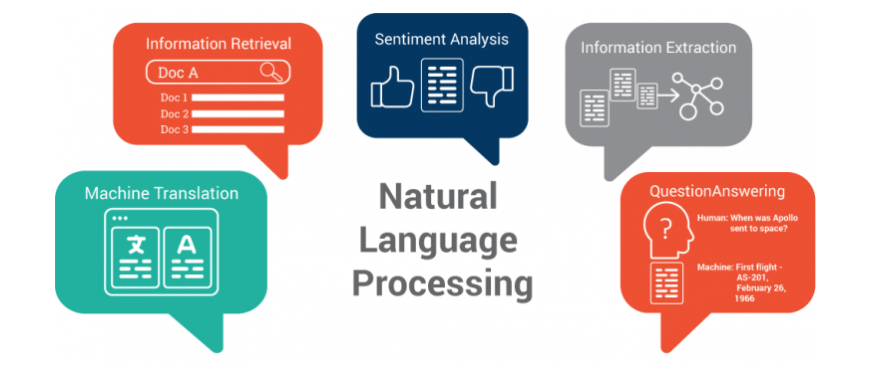
Mentioned in the Data Science page, Natural Language Processing (NLP) is a form of supervised machine learning. NLP essentially reads, deciphers, and converts the human language to a manner that is understandable to machines. The NLP code needs to be trained before it is able to do it's job–which is to parse text and output results upon the user's demand. Examples of NLP are Siri, spell-check, spam filters, and voice text messaging. Currently, NLP is very difficult since the human language is very complex, but people see hope in Deep Learning to solve more complex NLP problems.
There are two very common techniques used in NLP:
1. Syntactic Analysis: analyzes how the natural language follows grammatical rules and tries to derive meaning from the words.
Example: Part-of-speech tagging identifies the part of speech for each word
2. Semantic Analysis: analyzes the meaning of the group of words and is the difficult aspect of NLP
Example: Named entity Recognition (NER) determines which subset of words can be categorized together as one group
There are two very common techniques used in NLP:
1. Syntactic Analysis: analyzes how the natural language follows grammatical rules and tries to derive meaning from the words.
Example: Part-of-speech tagging identifies the part of speech for each word
2. Semantic Analysis: analyzes the meaning of the group of words and is the difficult aspect of NLP
Example: Named entity Recognition (NER) determines which subset of words can be categorized together as one group
Chemdataextractor
An example of a NLP program is Chemdataextractor.(Check out chemdataextractor.org/!) This python package is able to parse many different file types, including html's, xml's, pdf's, etc., and output a variety of useful chemistry-related data, such as chemical named entities, abbreviation definitions, and chemical records. It incorporates NLP in it's code, and is split into 5 main stages: Tokenization, Part-of-Speech Tagging, Named Entity Recognition, Phrase Parsing, and Information Extraction.

This image was taken from the Chemdataextractor documentation, which can be accessed here: chemdataextractor.org/docs/intro
Tokenization
In this step, the program segments the text into sentences or words and removes certain unneeded characters, like some punctuation. The smaller pieces of text are then called tokens.
For example with sentence "US20190241449A1 - Process for the removal of iron and phosphate ions from a chlorinated hydrocarbon waste stream- Google Patents", the program will print:
For example with sentence "US20190241449A1 - Process for the removal of iron and phosphate ions from a chlorinated hydrocarbon waste stream- Google Patents", the program will print:

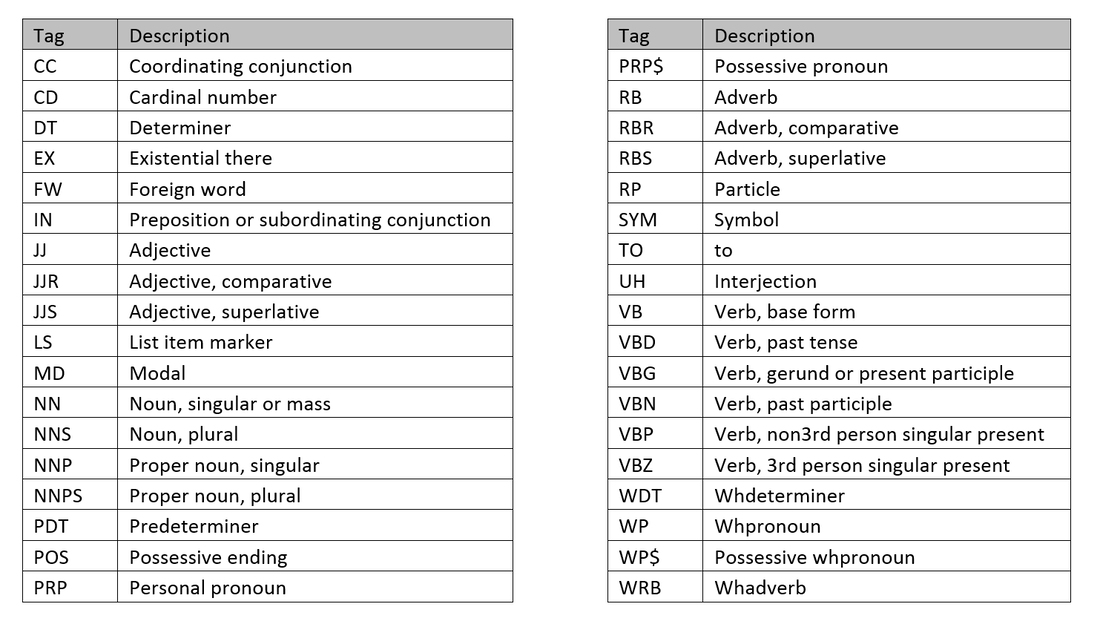
Part-of-Speech Tagging
As mentioned above, Part-of-speech tagging labels every word in the text with their designate part of speech.
For example, with sentence "1H NMR spectra were recorded on a 300 MHz BRUKER DPX300 spectrometer.", the program will print:
For example, with sentence "1H NMR spectra were recorded on a 300 MHz BRUKER DPX300 spectrometer.", the program will print:

Below are the definitions for each acronym:
Named Entity Recognition
In this step, the program is able to identify specific chemical entities and where that entity is located. Using the code, it will return a Span, which includes the text and start and end character number.
Phrase Parsing
The phrase parser takes a long sentence as is able to split it into constituents with labels, specifically noun phrases, verb phrases, and prepositional phrases. NP stands for noun phrase, VP stands for verb phrase, and PP stands for prepositional phrase.
For example, with the phrase "The quick brown fox jumped over the lazy dog", the program will print out:
For example, with the phrase "The quick brown fox jumped over the lazy dog", the program will print out:

Information Extraction
Through use of NLP, informational extraction is the process of automatically identifying and taking out specific structured information from machine-readable documents and other forms of texts. One example of information extraction is the process of emails extracting only the dates from messages for you to add to your calendar.
Image Citations
References
“An Introduction to Text Processing and Analysis with R.” Michael Clark: 9 Sept. 2018, m-clark.github.io/text-analysis-with-R/part-of-speech-tagging.html.
Duta, Debashree. “Information Extraction.” LinkedIn, 17 Jan. 2018, www.linkedin.com/pulse/information-extraction-debashree-dutta.
Nóra Ambróz, et al. “Natural Language Processing: A Short Introduction To Get You Started |.” Aliz, 14 Nov. 2019, aliz.ai/natural-language-processing-a-short-introduction-to-get-you-started/.
Pantech. “Natural Language Processing (NLP) Projects Using Raspberry Pi or Windows.” Pantech Blog, 21 May 2019, www.pantechsolutions.net/blog/natural-language-processing-projects-using-raspberry-pi-or-windows/.
“The Phrase Parser.” Index.mark, www.link.cs.cmu.edu/link/ph-explanation.html.
“An Introduction to Text Processing and Analysis with R.” Michael Clark: 9 Sept. 2018, m-clark.github.io/text-analysis-with-R/part-of-speech-tagging.html.
Duta, Debashree. “Information Extraction.” LinkedIn, 17 Jan. 2018, www.linkedin.com/pulse/information-extraction-debashree-dutta.
Nóra Ambróz, et al. “Natural Language Processing: A Short Introduction To Get You Started |.” Aliz, 14 Nov. 2019, aliz.ai/natural-language-processing-a-short-introduction-to-get-you-started/.
Pantech. “Natural Language Processing (NLP) Projects Using Raspberry Pi or Windows.” Pantech Blog, 21 May 2019, www.pantechsolutions.net/blog/natural-language-processing-projects-using-raspberry-pi-or-windows/.
“The Phrase Parser.” Index.mark, www.link.cs.cmu.edu/link/ph-explanation.html.
